
iris数据集中有五个变量,其中Species表示鸢尾属花的子类,其它四个变量分别是花瓣和萼片的长度和宽度。你可以用head(iris)来观察原始数据的一些样本。我们的第一个任务是想计算不同种类花在四个指标上的平均值。用到的函数有tapply,by及aggregate。这篇文章对它们有所涉及。
将数据解包后,先用tapply函数尝试,但会发现该函数一次只允许输入一个变量。如果要完全四个变量的计算可能得用到循环。放弃这个函数来试试用by函数,该函数可以一次输入多个变量,但输出结果为一个list格式,还需要用do.call函数进行整合,有点麻烦。最方便友好的还是aggregate函数,直接输出为数据框格式。另外它还允许用公式来设置分组因子。
attach(iris)
names(iris)
tapply(X=Sepal.Length,INDEX=Species,FUN=mean)
temp <-by(data=iris[,1:4],INDICES=Species,FUN=mean)
do.call(rbind,temp)
aggregate(x=iris[,1:4],by=list(Species),FUN=mean)
aggregate(.~ Species, data = iris, mean)
aggreagate函数表现已然不错,但还不够强大。比如说它没法直接得出表格的边际值,所以下面就请出本场的主角,即reshape包中的两员大将:melt与cast。这两个通常是配合使用,melt专门负责“融合”原始数据,形成长型(long)数据结构。cast则专职将融合后的数据“重铸”为新的形式(让人想起了“铁索连环”)。基本上只要有这两个函数,就能统一解决所有的汇总问题。还是以上面的问题为例子,先加载reshape包,然后用melt函数进行融合数据,其中参数id指定了用Species为编号变量,measure参数用来指定分析变量(即被融合的变量),本例中只指定了参数id,所以原始数据中未包括在id中的其它变量均指定为分析变量。你可以观察到新的数据iris.melt其实就是堆叠(stack)后的数据。然后我们再用cast来重铸,cast函数中可以使用公式,波浪号左侧变量将纵列显示,右侧变量将以横行显示。margins参数设定了以列作为边际汇总方向。如果希望在计算中只包括两种花,可以使用subset参数。
library(reshape)
iris.melt <- melt(iris,id='Species')
cast(Species~variable,data=iris.melt,mean,margins="grand_row")
cast(Species~variable,data=iris.melt,mean,
subset=Species %in% c('setosa','versicolor'),
margins='grand_row')
reshape包的作者也是ggplot2包的开发者,这个牛人是个完美主义者,在reshape包推出五年后,他重构代码推出了新的reshape2包。这个新包的特性在于:- 改进算法,使计算与内存使用效能增强;
- 用dcast和acast代替了原来的cast函数;
- 用变量名来设定边际参数;
- 删除cast中的一些特性,因为他确认plyr包能更好的处理;
- 所有的melt函数族都增加了处理缺失值的参数。
library(reshape2)
library(ggplot2)
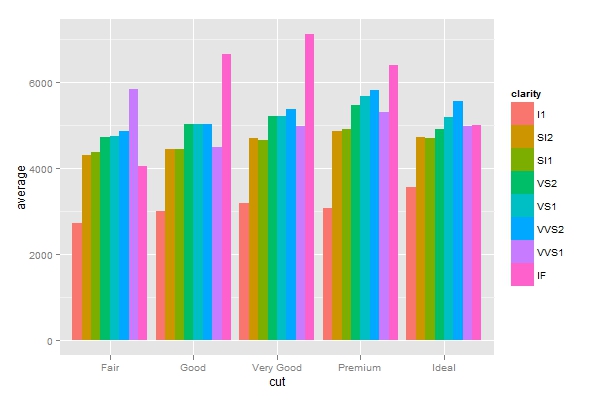
data <- diamonds[1:7]
data.melt <- melt(data,id=c('cut','color','clarity'))
diam.sum <- dcast(data.melt,cut+clarity~variable,
subset=.(variable %in% c('price','carat')),mean)
diam.sum$average <- diam.sum$price/diam.sum$carat
p <- ggplot(diam.sum,aes(cut,average,fill=clarity))
p + geom_bar(position='dodge')
没有评论:
发表评论