
这两种方法的共同点在于,将解释变量的系数加入到Cost Function中,并对其进行最小化,本质上是对过多的参数实施了惩罚。而两种方法的区别在于惩罚函数不同。但这种微小的区别却使LASSO有很多优良的特质(可以同时选择和缩减参数)。下面的公式就是在线性模型中两种方法所对应的目标函数:


在R语言中可以使用glmnet包来实施套索算法。我们采用的数据集是Machine Learning公开课中第七课的一个算例。先来看看这个样本数据的散点图。下图显示有两个类别等待我们来区分。显然其决策边界是非线性的,所以如果要用Logistic Regression来作分类器的话,解释变量需要是多项式形式。但这里存在一个问题,我们应该用几阶的多项式呢?如果阶数过高,模型变量过多,会存在过度拟合,而反之阶数过少,又会存在拟合不足。所以这里我们用LASSO方法来建立Logistic回归分类器。

- 根据算例要求,先生成有六阶多项式的自变量,这样一共有28个自变量;
- 用glmnet包中的cv.glmnet函数建模,该函数自带交叉检验功能;
- 根据上面的结果绘制CV图如下,从中选择最佳lambda值。
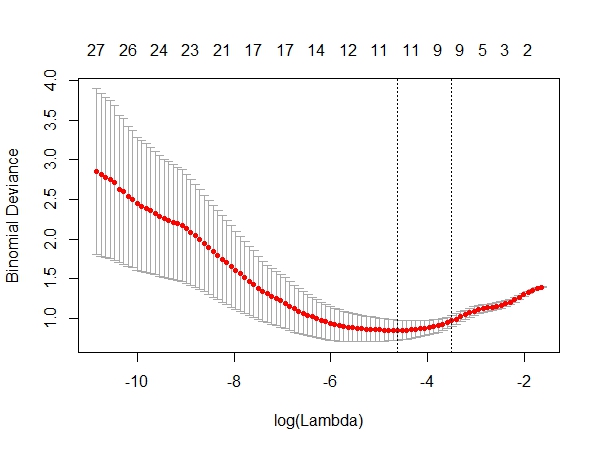
在使用cv.glmnet函数选择lambda值之后,我们没有必要去运行glmnet函数,直接从结果中就可以提取最终模型(9个变量)并获得参数系数。为了利于比较我们还提取了原始模型(28个变量)的参数系数。
最后我们要在原来的散点图上画出两条决策边界,一条是根据LASSO方法得到的9变量模型,下图中紫色曲线即是它决策边界,决策边界比较平滑,具备很好的泛化能力。另一条是28个变量的原始模型。 蓝色曲线即是它的决策边界,它为了拟合个别样本,显得凸凹不平。

参考资料:
《The Elements of Statistical Learning》
《Machine Learning for Hackers》
http://www-stat.stanford.edu/~tibs/lasso.html
http://datamining.dongguk.ac.kr/ftp/temp/Regularization.pdf
http://ygc.name/2011/10/26/machine-learning-5-2-regularized-logistic-regression/
本例的R代码在此。
博主能不能把图和code里面用到的example 数据也上载一下,
回复删除我想重复run一下你的code, 看看每一步产生的中间数据, 但是没有找到d:/ex2data2.txt. 谢谢
到这下载吧,https://www.box.com/s/6hqr9ep9mgiqqbiv3kr8
删除上面的链接失效了
删除数据参考这里 https://github.com/merwan/ml-class/blob/master/mlclass-ex2/ex2data2.txt
删除谢谢大侠的例子,加深了regulation的理解
回复删除好东西
回复删除