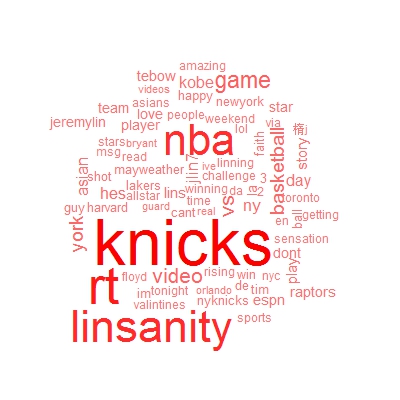
看看上面的词云图吧。恩...所属的knicks队名出现频率高是应该的,网络上流传的外号linsanity真得是很热啊,还有不少将他和kobe bryant相比较。剩下的各位慢慢研究吧。
R代码:
#载入用到的包
library(twitteR)
library(tm)
library(wordcloud)
#设定搜索标签,提取1000个推文并转化为数据框
searchTerm = '#Jeremy Lin'
raw.data <- searchTwitter(searchTerm,n=1000)
tw.df <- twListToDF(raw.data)
#为了回避一些推文中的网址,用文本函数gsub加以去除
Remove <- function(tweet) {
gsub("http+", "", tweet)
}
tweets <- as.vector(sapply(tw.df$text, Remove))
#用tm包中的Corpus读取文本并生成语料库对象,再对其进行预处理
tw.corpus <- Corpus(VectorSource(tweets))
tw.corpus <- tm_map(tw.corpus, stripWhitespace)
tw.corpus <- tm_map(tw.corpus, removePunctuation)
tw.corpus <- tm_map(tw.corpus,tolower)
tw.corpus <- tm_map(tw.corpus,removeWords,stopwords('english'))
#生成词频矩阵
doc.matrix <- TermDocumentMatrix(tw.corpus,control = list(minWordLength = 1))
dm <- as.matrix(doc.matrix)
v <- sort(rowSums(dm),decreasing=T)
d <- data.frame(word=names(v),freq=v)
#去除Jeremy和Lin这两个词后,生成最后的词云
data <- d[c(-1,-2),]
mycolors <- colorRampPalette(c("white","red"))(200)
wc <-wordcloud(data$word,data$freq,min.freq=15,colors=mycolors[100:200])
请问wordcloud在哪里下?thx
回复删除你是说这个扩展包吗?可以在R里面输入 install.packages('wordcloud') 进行安装,然后library(wordcloud) 加载就可以了。当然要在联网状态。
删除what's wrong with the twitter authentication?
回复删除OAuth authentication is required with Twitter's API v1.1
How can I be authenticated?
installation of package ‘wordcloud’ had non-zero exit status.....不知道这种情况怎么办?求指点,谢谢!
回复删除安装包不成功,多半是有些依赖不满足,需要仔细看安装过程的信息。
删除