
第一步:我们先画出这些变量的相关系数图,以剔除一些冗余的变量,从下图可看到深兰色方块即表示两组数据间有较强正相关,那么我们只需取其中一组数据即可,例如TRB(篮板总数)就可以代替ORB/DRB/BUK。由此我们提取MP/FGA/FGP/X3PP/FT/FTP/TRB/AST/STL/PF/TOV/PTS这12个变量作进一步处理。

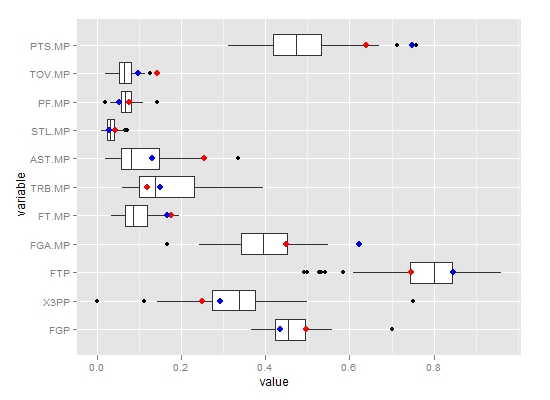
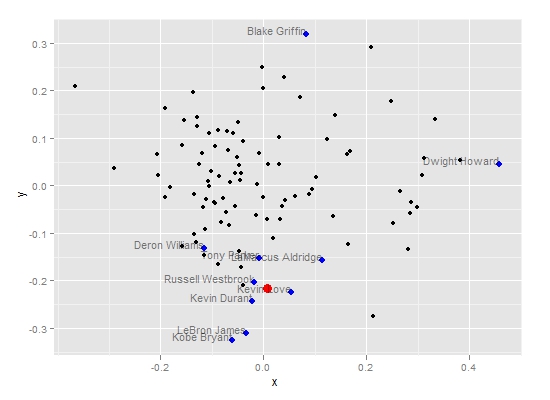
第三步:上面对各指标分别进行了一维的比较,下面用多维标度分析方法,将多维空间的对象简化到低维空间进行定位和分析。提取前两维绘制成散点图如下。其中红色点表示是林同学的位置,而蓝色点则是总得分排名前十位的球员。从图上似乎可以得到令人吃惊的结论,那就是林同学几乎可与这十位巨星球员归为一类了。
R代码:
#读取CSV数据文件
data <- read.csv('d:/nba.csv',sep=',')
summary(data)
#绘制变量间的相关系数图
library(corrgram)
corrgram(data[,c(-1,-2)])
#将几个指标除以上场时间,再合成为新的数据
temple.data <- sapply(data[c('FGA','FT','TRB','AST','STL','PF','TOV','PTS')],function(x) x/data['MP'])
newdata1 <- cbind(data[c('FGP','X3PP','FTP')],as.data.frame(temple.data))
#对数据进行融合以方便ggplot2绘图
library(reshape)
newdata2 <- melt(newdata1)
library(ggplot2)
#提取林书豪与科比的数据
lindata<-melt(newdata1[101,])
kobedata <-melt(newdata1[1,])
#构建ggplot图层的基本数据层
p <- ggplot(data=newdata2,aes(x=variable,y=value))
#添加箱线图和点图
p + geom_boxplot()+
geom_point(data=lindata,colour='red',size=3)+
geom_point(data=kobedata,colour='blue',size=3)+
coord_flip()
#加载MASS包进行MDS分析
library(MASS)
nba.mds <- isoMDS(dist(newdata1))
#提取前两维数据
x = nba.mds$points[,1]
y = nba.mds$points[,2]
mds.data <-data.frame(x,y,player=data$Player)
lin.data <- mds.data[101,]
topten.data <- mds.data[1:10,]
#绘制散点图
g <- ggplot(data=mds.data,aes(x,y))
g + geom_point()+
geom_point(data=lin.data,color='red',size=4)+
geom_point(data=topten.data,color='blue',size=3)+
geom_text(size=4,data=topten.data,aes(label=player),hjust=1,vjust=0,alpha=0.5)
变量说明:
G:出场次数
GS:先发次数
MP:上场时间
FG:投中次数
FGA:投篮次数
FGP:命中率
3P:3分命中次数
3PA:3分投篮次数
3PP:3分命中率
FT:罚球命中次数
FTA:罚球次数
FTP:罚球命中率
ORB:进攻篮板
DRB:防守篮板
TRB:总篮板
AST:助攻
STL:盗球
BLK:封盖
TOV:失误
PF:个人犯规
PTS:总得分
变量名后加.MP的表示以上场时间进行了平均处理。
拜老大的神文!!!!!!
回复删除感谢分享...
回复删除您的文章太有帮助了谢谢~
回复删除