
时点类函数,它包括了解析、抽取、修改。
# 从字符型数据解析时间,会自动识别各种分隔符
> x <- ymd('2010-04-08')
# 观察x日期是一年中的第几天
> yday(x)
# 修改x日期中的月份为5月
> month(x) <- 5
时段类函数,它可以处理三类对象,分别是:
- interval:最简单的时段对象,它由两个时点数据构成。
- duration:去除了时间两端的信息,纯粹以秒为单位计算时段的长度,不考虑闰年和闰秒,它同时也兼容基本包中的difftime类型对象。
- period:以较长的时钟周期来计算时段长度,它考虑了闰年和闰秒,适用于长期的时间计算。以2012年为例,duration计算的一年是标准不变的365天,而period计算的一年就会变成366天。
# 从两个时点生成一个interval时段数据
> y <- new_interval(x,now())
# 从interval格式转为duration格式
> as.duration(y)
# 时点+时段生成一个新的时点
> now() + as.duration(y)
# 10天后的时间数据
> now() + ddays(10)
# 下面的两条语句很容易看出duration和period的区别,dyears(1)表示duration对象的一年,它永远是365天。而years(1)表示period对象的一年,它识别出2012是闰年,它有366天,所以得到正确的时点。
> ymd('20120101') + dyears(1)
[1] "2012-12-31 UTC"
> ymd('20120101') + years(1)
[1] "2013-01-01 UTC"
为了处理时区信息,lubridate包提供了三个函数:
- tz:提取时间数据的时区
- with_tz:将时间数据转换为另一个时区的同一时间
- force_tz:将时间数据的时区强制转换为另一个时区
# 输入欧洲杯决赛在乌克兰的开场时间,再转为北京时间
eurotime <- ymd_hms('2012-07-01 21:45:00',tz='EET')
with_tz(eurotime,tzone='asia/shanghai')
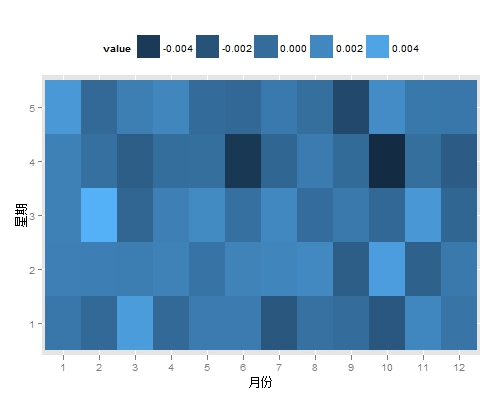
最后来玩玩股票指数作为结束吧,在金融市场中谣传着一种日历效应。即在一周的第一天或者一年的第一个月份,股票会出现不错的上涨。让我们用热图来观察一下。首先是获取上证指数数据,然后根据不同的月份和星期数,将收益率汇集到不同的组中。将该组收益率的中位数映射到图形颜色上去。可以从下图看到,似乎并不存在明显周一效应或是一月效应。
library(quantmod)
library(ggplot2)
library(lubridate)
# 读取上证指数历史数据
getSymbols('^SSEC',src='yahoo',from = '1997-01-01')
time <- ymd(as.character(index(SSEC)))
open <- as.numeric(Op(SSEC))
high <- as.numeric(Hi(SSEC))
low <- as.numeric(Lo(SSEC))
close <- as.numeric(Cl(SSEC))
volume <- as.numeric(Vo(SSEC))
# 根据收盘和开盘计算当日收益率
profit <- (close-open)/open
# 提取时间数据中的周数和月份
wday <- wday(time)-1
mday <-month(time)
data <- data.frame(time,wday,mday,profit)
p <- ggplot(data,aes(factor(mday),factor(wday),z=profit))
# 收益率的热图,图中颜色越浅,表示汇集到这个组中的收益率中位数越高
p +stat_summary2d(fun=function(x) median(x))+
opts(legend.position = "top")+ labs(x='月份',y='星期')
http://statistics.berkeley.edu/classes/s133/dates.html
http://www.jstatsoft.org/v40/i03/paper
http://rlogs.sinaapp.com/post/r-package-lubridate.html
没有评论:
发表评论