我们先构造一些人为数据,它是基于sin函数和cos函数构成的两组点。如果我们用传统的K均值聚类,结果如下图所示。其聚类结果是不理想的,因为它不能识别非球形的簇。

为了解决这个问题,我们可以使用DBSCAN方法,它是一种基于密度的聚类方法。即寻找那些被低密度区域所分离的高密度区域。DBSCAN方法的重要概念如下:
- 核心点:如果某个点的邻域内的点的个数超过某个阀值,则它是一个核心点,即表示它位于簇的内部。邻域的大小由半径参数eps决定。阀值由MiniPts参数决定。
- 边界点:如果某个点不是核心点,但它落在核心点的邻域内,则它是边界点。
- 噪声点:即非核心点也非边界点。

在上图中,红色的点均为核心点,黄色的为边界点,而蓝色的则为噪声点。简单来讲,DBSCAN的算法是将所有点标记为核心点、边界点或噪声点,将任意两个距离小于eps的核心点归为同一个簇。任何与核心点足够近的边界点也放到与之相同的簇中。下面我们来使用R语言中的fpc包来对上面的例子实施密度聚类。其中eps参数设为0.6,即两个点之间距离小于0.6则归为一个簇,而阀值MinPts设为4。
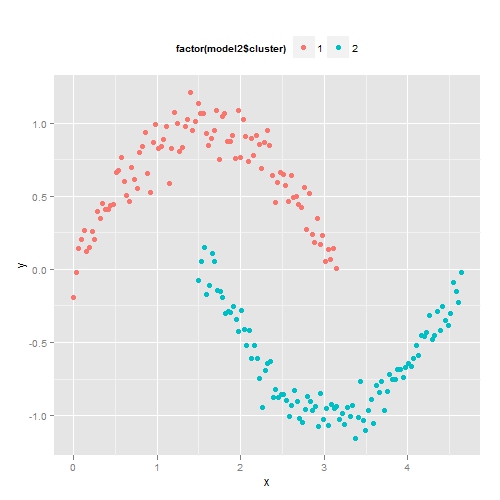
从这个例子中,我们可以看到基于密度聚类的优良特性,它可以对抗噪声,能处理任意形状和大小的簇,这样可以发现K均值不能发现的簇。但是对于高维数据,点之间极为稀疏,密度就很难定义了。
参考资料:
数据挖掘导论
http://en.wikibooks.org/wiki/Data_Mining_Algorithms_In_R/Clustering/Density-Based_Clustering
R代码如下:
# 生成数据
x1 <- seq(0,pi,length.out=100)
y1 <- sin(x1) + 0.1*rnorm(100)
x2 <- 1.5+ seq(0,pi,length.out=100)
y2 <- cos(x2) + 0.1*rnorm(100)
data <- data.frame(c(x1,x2),c(y1,y2))
names(data) <- c('x','y')
# 用K均值聚类
model1 <- kmeans(data,centers=2,nstart=10)
library(ggplot2)
p <- ggplot(data,aes(x,y))
p + geom_point(size=2.5,aes(colour=factor(model1$cluster)))+
opts(legend.position='top')
# 用fpc包中的dbscan函数进行密度聚类
library('fpc')
model2 <- dbscan(data,eps=0.6,MinPts=4)
p + geom_point(size=2.5, aes(colour=factor(model2$cluster)))+
opts(legend.position='top')
如果随机误差取为NORM(0,1).结果太差了。
回复删除你这样去0.1,意义不大啊。
密度聚类的假设是簇之间有低密度区域,如果随机误差取为NORM(0,1),二组就混在一起了,结果当然就差了。这里只是用这个人造数据来做例子,说明当K均值聚类不行的情况下,密度聚类可以行。
删除第一个例子不好吧,没人拿全局距离去聚类,都是基于local density的。K-NN就是一个非常有效的算法,如果加上2次迭代,效果非常的好。
回复删除楼主如果能分析一下高维的聚类就更好了,这部分虽然做了很多,但是感觉还有进步空间