
在决策树建模中需要解决的重要问题有三个:
- 如何选择自变量
- 如何选择分割点
- 确定停止划分的条件
在R语言中关于决策树建模,最为常用的有两个包,一个是rpart包,另一个是party包。我们来看一下对于上述问题,这两个包分别是怎么处理的。
rpart包的处理方式:首先对所有自变量和所有分割点进行评估,最佳的选择是使分割后组内的数据更为“一致”(pure)。这里的“一致”是指组内数据的因变量取值变异较小。rpart包对这种“一致”性的默认度量是Gini值。确定停止划分的参数有很多(参见rpart.control),确定这些参数是非常重要而微妙的,因为划分越细,模型越复杂,越容易出现过度拟合的情况,而划分过粗,又会出现拟合不足。处理这个问题通常是使用“剪枝”(prune)方法。即先建立一个划分较细较为复杂的树模型,再根据交叉检验(Cross-Validation)的方法来估计不同“剪枝”条件下,各模型的误差,选择误差最小的树模型。
party包的处理方式:它的背景理论是“条件推断决策树”(conditional inference trees):它根据统计检验来确定自变量和分割点的选择。即先假设所有自变量与因变量均独立。再对它们进行卡方独立检验,检验P值小于阀值的自变量加入模型,相关性最强的自变量作为第一次分割的自变量。自变量选择好后,用置换检验来选择分割点。用party包建立的决策树不需要剪枝,因为阀值就决定了模型的复杂程度。所以如何决定阀值参数是非常重要的(参见ctree_control)。较为流行的做法是取不同的参数值进行交叉检验,选择误差最小的模型参数。
下面我们用iris数据集,分别用两个包的默认参数来建模,观察其图形结果。rpart包的内置绘图功能不强,因此使用partykit包来绘制rpart建模对象。
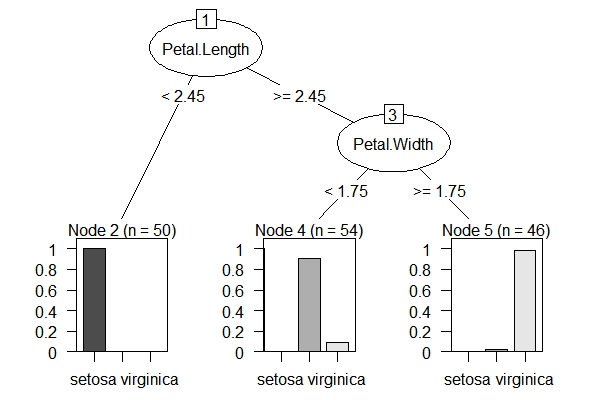
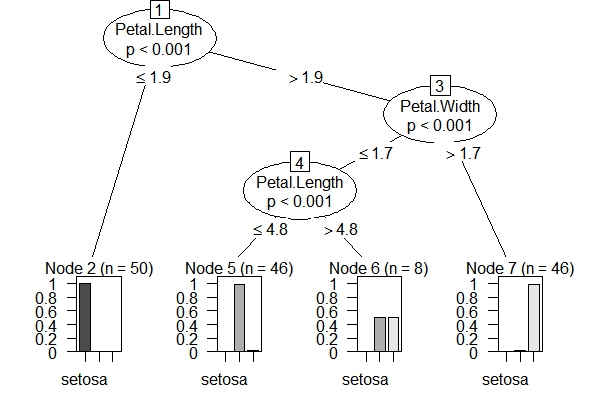
出了决策树模型之外,这两个包也分别提供了集成学习方法随机森林,基于rpart包的随机森林是randomForest包,而基于party包的随机森林即cforest函数。
randomForest包并不依赖rpart,自己实现的决策树和tree包有点类似
回复删除原来这样,我还纳闷呢,randomForest怎么是独立的包,原来还是依赖了决策树。
回复删除那这样,直接使用randomForest不是更好?模型选择依据是什么呢?
删除选择依据一般就是靠多重检验
回复删除可能刚才那句话表述不太对,我的意思是“需要用决策树的地方,不如都直接用randomForest好了(也或者其他ensemble的方法)”如果不考虑速度,这样还有啥问题吗?
删除没啥问题,现在实务都用ensemble了。但决策树可以做研究用嘛。
删除哦原来这样子,一下子把我这里那里的疑问都打通了,实务就是不一样啊,可惜没机会接触到。希望博主多出案例,学习了!
删除我又想了想,比起随机森林,决策树容易可视化一些,也可以把最终模型直接发布给使用者,即使用者不懂模型,对于新进入的样本,也可以按结果直接分类,随机森林的话,则每次新进入的都要跑程序。随机森林应该没办法让一个门外汉来给新样本分类吧?那你所谓的“在实务中”,用的都是一堆懂模型的,不涉及给门外汉用吗?
删除PS,这么纠结你一定想把我扔回火星,但还是,搭理下嘛搭理下嘛。。。
看最终目的是什么,决策树是有解释能力的,这是很不错的,其它一些比如神经网络、随机森林则是黑盒模型。有时候目的就是预测,就用黑盒模型,好比鸡叫不能解释日出,但可以预测日出。
删除这些我都想过,但是因为没有人交流,所以对自己的想法没什么自信,怕有更好的,谢谢你给了我一个确信的答案。
删除rpart这几个包都是基于CART算法的吧?我记得博主有一篇关于C5.0的文章,还做过比较。那么R里面有没有和C5.0一样基于Decision Tree的包(C4.5 甚至 ID3都行)??
回复删除试试weka,用R来调
删除强迫症患者提醒: “阀(fá)值”是一个错误的用词,其正确用法是“阈(yù)值”
回复删除