Data Science is the art of turning data into actions
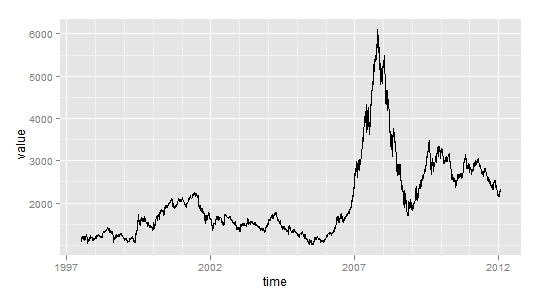
library(quantmod) library(ggplot2) getSymbols('^SSEC',src='yahoo',from = '1997-01-01') close <- (Cl(SSEC)) time <- index(close) value <- as.vector(close) p <- ggplot(data.frame(time,value),aes(time,value)) p + geom_line()
library(ggplot2) p <- ggplot(mpg, aes(cty, hwy)) p1 <- p + geom_point(aes(colour = factor(year),shape = factor(year), size = displ), alpha = 0.6, position = 'jitter') print(p1)
library(ggplot2) with(mpg,table(class,year)) p <- ggplot(data=mpg,aes(x=class,fill=factor(year))) p + geom_bar(position='dodge') p + geom_bar(position='stack') p + geom_bar(position='fill') p + geom_bar(position='identity',alpha=0.3)

.jpg)